
本文介绍了2023年7月成立的人工智能公司 DeepSeek(深度求索),该公司以低成本高性能开源了性能媲美 OpenAI o1 的大语言模型,在2025年春节期间在国内外爆火,甚至有人称这是国运级的创造,真有那么神么?让我们一起来看看。
DeepSeek 公司简介
DeepSeek(深度求索)是一家成立于2023年7月的中国人工智能公司,总部位于杭州,由知名量化资管机构幻方量化孵化,创始人梁文锋。公司定位为"探索通用人工智能(AGI)本质"的科技企业,专注于大语言模型(LLM)研发。
产品概览
1 | timeline |
我们重点介绍 V3 与 R1 两款产品:
DeepSeek 热度来源
第一个是性能。在多个基准测试中,V3的能力超过了许多开源对手,例如Meta公司的Llama-3.1模型和阿里巴巴的Qwen2.5模型。跟不了解这块的同学解释一下,Meta就是之前的Facebook,而Llama模型则是AI开源模型中一直处于顶尖水平的产品。在DeepSeek官网上,他们不仅展示了与其他开源模型的对比数据,还在多个任务中与OpenAI和Claude这类闭源模型进行了能力对比。一般情况下,顶级闭源模型的能力通常优于开源模型,但DeepSeek在代码生成、数学运算等方向表现出了非凡的实力。
第二个是在有限资源下的成本控制。这也是让其他同行视其为研究对象的核心原因。
我用几个数字来说明,你就能理解为什么其他企业对此感到震惊了:DeepSeek的V3模型只用了2048张英伟达H800显卡,两个月时间,便训练出了一个拥有6710亿参数的超大规模模型,训练成本约为550万美元。
数据对比后,DeepSeek的厉害之处更为明显。如果是其他硅谷公司来完成同等能力的模型,通常会选择最高端的英伟达显卡,而不是价格较低的H800显卡。
此外,他们至少需要1.6万块高端显卡才能达到类似水平,远无法像DeepSeek这样仅用2000块H800显卡完成任务。从算力上看,V3的训练耗费仅为同等规模硅谷公司模型的十一分之一。而在成本上,Meta的同等能力模型训练花费高达数亿美元,完全无法与DeepSeek的性价比相提并论。
在拥有媲美商业模型的性能的同时,DeepSeek选择全面开源,这在AI领域是非常少见的。
在我的印象中,如果一家公司没有持续的技术创新,那么它开源自己最新的技术,无异于把自己的优势拱手让人,毕竟比起算力或资金实力 DeepSeek不占优势。但开源也给 DeepSeek 带来了很多好处,首先它在用户使用协议中说明了可能使用用户的数据用于训练模型[1],这样可以让模型更快的迭代。
DeepSeek V3 与 R1 的区别
DeepSeek V3 作为通用的大语言模型,其性能表现在多个基准测试中均领先同类产品。而 R1 则是一款开源的推理模型,擅长处理复杂任务且可免费商用。两者在应用场景和擅长领域上有较大差异,下面我们将详细介绍。
-
通用模型擅长: 文本生成、创意写作、多轮对话、开放性问答、摘要生成
-
推理模型擅长: 数学推导、逻辑分析、代码生成、复杂问题拆解
-
通用模型: 需显式引导推理步骤(如通过CoT提示),否则可能跳过关键逻辑。
-
推理模型: 提示语更简洁,只需明确任务目标和需求(因其已内化思维链具有逻辑推理能力)。无需逐步指导,模型自动生成结构化推理过程(若强行拆解步骤,反而可能限制其能力)。
之前在第一次用 DeepSeek R1 时,默认使用了以前使用的提示词,但 R1 的回答就特别不靠谱,我一度以为 R1 的能力不如 V3,后面去除提示词,R1 的回答就特别靠谱了。其逻辑推理能力真的很强,但是需要用户提供更多的信息,而不是像 V3 那样只需要一个提示词就能回答。换句话说 R1 需要更好的描述问题,问题越具体,回答越准确。
在使用过程中我发现,使用 DeepSeek R1 总结论文,或者生成摘要时,效果不如 DeepSeek V3。
后续在了解 DeepSeek R1 的技术原理后知道,R1 是使用具有确定答案的方法训练出来的,换句话说 R1 使用了大量的数学和代码类问题训练出来的,所以也更加适合逻辑推理等有具体或确定答案的资料,当然这就特别符合我工作中的使用场景,需要具体且精确不需要创意的回答。
DeepSeek 目前存在的问题与挑战
据Get笔记开发者,快刀青衣提到过,Get笔记使用 DeepSeek 时,时常在下午4点到6点出现接口返回慢的问题[2],在 DeepSeek API 接受大量请求时,会出现接口返回慢的问题,这也是 DeepSeek 目前存在的问题之一。
在 2025年春节期间,DeepSeek 也遭受了大量国外黑客的 DDos 攻击,导致 DeepSeek 服务不可用, 如下图 DeepSeek 服务状态图[3]所示:
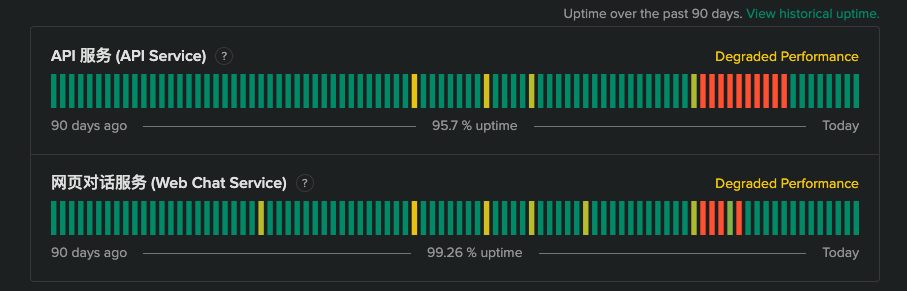
在过完年回来, DeepSeek 因为过于火爆,导致了 API 充值通道关闭,我的额度用完了,每天都刷新好几次,但是都没有充值的按钮,只能等待 DeepSeek 的 API 充值通道重新开放。
同时,OpenAI 也发布了 Operator、DeepResearch,这也是 DeepSeek 目前面临的竞争。
DeepSeek 因为其开源的特性,也得到了诸多厂家支持,AMD、华为云、硅基流动、国家超算平台都相继宣布与 DeepSeek 合作,部署 DeepSeek 服务。也减轻了 DeepSeek 自己服务器的压力。
DeepSeek SWOT 分析
结合如上所述,我们对 DeepSeek 进行 SWOT 分析:
- 优势:开源多样部署、上手快准确率高、不需翻墙
- 劣势:工程能力弱,服务可用度不稳定,与 O1 相比优势不够明显。“代码不等于产品”——API 服务状态与商业化支持不足
- 机会:国内 AGI 市场尚在快速扩张,政策红利与需求旺盛
- 威胁:OpenAI DeepResearch、其他大厂自研 LLM 带来竞争压力
常见疑问与解答
DeepSeek有5万张H100吗?
这方面传言最夸张的是Scale AI公司的CEO亚历山大·王的说法。他在接受CNBC采访时说,DeepSeek有大约5万张H100,但因为有美国的出口管制,所以DeepSeek不能公开说。
比较靠谱的分析来自Semianalysis最新一篇对DeepSeek的深度分析报告。我把链接放在文稿中了。当然,今天已经有很多上万字的中文翻译版了,感兴趣可以逐字逐句看。我简要地说一下结论:
Semianalysis认为,DeepSeek一共6万张计算卡,其中A100、H800、H100各1万张,H20还有3万张。
咱们以H100为标准,假如它的算力值是100的话,其他几张卡的算力都是多少呢?A100是它的上一代,算力大约50;H800是H100的第一次阉割版本,算力60;H20是H100的第二次阉割版,算力15。之所以阉割两次,是因为美国前后两次出台芯片禁令,英伟达不得不配合禁令为中国生产阉割版计算卡。如果是5万张H100的话,算力应该是500万;而现在DeepSeek拥有6万张拼凑起来的计算卡,总算力是255万。
训练成本600万美元,真有这么低吗?
600万美元的说法,来自DeepSeek自己公布的V3模型的预训练费用。其中包含100万美元的14.8Ttoken的数据费用,还有460万美元的H800 GPU运行费用。这个费用就是按照算力对应的GPU时长和市面上租赁H800 GPU每小时的费用相乘得到的。两者相加,是560万美元。但还有其他费用没有计入——V3基础模型训练完,做微调后让它成为R1模型,还需要额外的100万美元。所以把基础模型的预训练和微调成R1整个算上,就是660万美元;不算微调就是560万美元。这就是600万美元训练成本的来源。
但DeepSeek毕竟不是租用算力做的模型,而是自己买卡,自己搭建服务器,自己人员高薪待遇搞研究、搞训练,所以硬件成本和人力成本都要计入成本,这些才占大头。
具体花费多少呢?还是依据Semianalysis的分析:购买GPU需要7亿美元;搭建服务器需要的其他零件、CPU、存储系统、操作系统的各种软件、冷却系统,这些需要9亿美元;这四年的运营成本加在一起还有9.44亿美元。总计大约26亿美元。
当然,由于今后开发新模型还会继续用到这些硬件,所以26亿美元并不能当作R1模型的训练成本,而是多年以后的总成本。
为什么 DeepSeek 有时候会说自己是GPT?
训练大语言模型的公司,除了OpenAI作为第一个开创者,所有的数据都需要自己操办之外,后续加入的公司,数据一般都不是自己搞定的,而是从专门的数据公司买的。
所以 DeepSeek 所使用训练数据很可能也是从专门的数据公司购买的,而早期的数据公司,很可能从 OpenAI API 接口下载数据,所以 DeepSeek 的数据和 OpenAI 的数据有很多相似之处,导致了你问 DeepSeek 他有时回答自己是 ChatGPT 的原因。
之前很多数据公司都瞄准了OpenAI薅羊毛,它们的训练数据如果清洗得不太干净,里面自然包含了很多原始出处的标签,别的模型拿这些数据训练,有时候就会回答自己是GPT。
DeepSeek 出现后,算力的需求是不是减弱了?
先说结论,算力的需求没有减弱,而是增加了。
V3和R1出现后,训练和推理成本大约下降了一个数量级,更多中小参与者也动念加入千卡、万卡的竞争中了。
个人使用感受
- DeepSeek V3 在论文中的性能测试中性能接近 OpenAI o1 的水平,在我使用的过程中,DeepSeek V3的回答与OpenAI GPT-4回答结果质量相当,并没有明显的优势。
- DeepSeek R1 在推理方面过程中,可以看到其思考的过程,使用起来更加直观,但是在生成摘要等方面,效果不如 DeepSeek V3。
- OpenAI o1 在推理方面速度更快,DeepSeek R1 的回答通常需要等待30s以上,才能生成的差不多。
- DeepSeek 的开源带动了国内的 AGI 研究,展示了我们国内的公司也可以做出技术领先的产品,给其他一直只是模仿和仿制,打价格战的公司树立了榜样。
- DeepSeek 的服务在春节回来后没有恢复,导致我无法使用,我使用了其他云平台提供的 API 进行访问,如 硅基流动、华为云等。
总结与展望
DeepSeek 作为一家年轻的AI公司,通过其创新的技术和开源策略在短时间内取得了显著成就,相信以后 DeepSeek 会继续在技术创新、商业化运营等方面取得更大突破。